PyTorch における DeepLabv3+ の学習コードの実装
- 概要
- DeepLabv3+ の概要
- Segmentation Models PyTorch の概要
- Segmentation Models PyTorch でエンコーダに利用する事前学習モデル
- 環境構築
- 学習に用いるデータセット
- 学習コードの実装
- 学習結果
- あとがき
概要
CNN 系のセグメンテーションモデルとして代表的な DeepLabv3+ の学習コードをなるべく簡単に実装する方法を紹介します。
GitHub 等には既に様々な実装が公開されていますが、原著論文を忠実に再現した前処理や高い拡張性を持たせてあるため、全体の処理はやや把握しにくい実装になっています。ここでは、簡便にセグメンテーションモデルが利用可能な Segmentation Models PyTorch などを活用しながら、見通しの良い学習コードを実装したいと思います。
DeepLabv3+ の概要
DeepLabv3+(2018) は DeepLabv3(2017) を拡張したセグメンテーションモデルです。DeepLabv3, DeepLabv3+ の特徴としては以下の通りです。
DeepLabv3
- Atrous 畳み込みの導入による広い視野(field of view)に対する特徴量の畳み込み
- Atrous 畳み込みを並列に用いた Atrous Spatial Pyramid Pooling(ASPP) モジュールの導入による様々なスケールの特徴量の畳み込み
ここでは、従来の MaxPooling による特徴量マップにおける解像度の低下を指摘し、Atrous 畳み込みや ASPP モジュールによる様々なスケールにおける特徴量の畳み込みに関する手法を提案しています。
DeepLabv3+
- DeepLabv3 に対してエンコーダ-デコーダ構造の導入による低レベルの特徴マップの利用
- エンコーダへの Xception の導入と、ASPP とデコーダへの Depthwise separable convolution の導入による計算効率の向上
ここでは DeepLabv3 を拡張し、エンコーダ-デコーダ構造によるオブジェクトの境界の鮮明化や Depthwise separable convolution による計算効率の向上を図っています。
最近の画像認識界隈では Vision Transformer がトレンドのようですが、CNN 系の画像認識としては DeepLabv3+ は主要なモデルの位置づけになると思います。この記事では、 Segmentation Models PyTorch を利用して DeepLabv3+ を簡便に実装していきたいと思います。
Segmentation Models PyTorch の概要
Segmentation Models PyTorch は様々なセグメンテーションモデルが統一的な API で利用できるライブラリです。
このライブラリでは以下のモデルが利用可能です。
- Unet
- Unet++
- MAnet
- Linknet
- FPN
- PSPNet
- PAN
- DeepLabV3
- DeepLabV3+
Quick Start に記載の通り、以下のようにインポートすることでモデルが利用できます。バックボーンのエンコーダや出力クラス数などもパラメータとして指定することで簡単に利用できるように設計されています。
import segmentation_models_pytorch as smp model = smp.Unet( encoder_name="resnet34", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7 encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization in_channels=1, # model input channels (1 for gray-scale images, 3 for RGB, etc.) classes=3, # model output channels (number of classes in your dataset) )
Segmentation Models PyTorch でエンコーダに利用する事前学習モデル
Segmentation Models PyTorch のエンコーダで利用できる事前学習モデルは大きく以下の2つがあります。
- Available Encoders (Torchvision のリポジトリ等で提供される事前学習モデル)
- Timm Encoders (PyTorch Image Models で提供される事前学習モデル)
Available Encoders
こちらは Torchvision のリポジトリ等で提供される事前学習モデルで、利用できるものは以下に一覧にされています。
ソースコード(例えば segmentation_models_pytorch/encoders/resnet.py)を読むと、 Torchvision で提供される事前学習モデルを利用していることがわかります。
一覧の中にはエンコーダの名前に timm と入っているものがありますが、次の Timm Encoders との具体的な違いはちょっとわかりませんでした。一応、こちらのエンコーダでは timm の API (timm.create_model) は使わずに timm のリポジトリで提供されている事前学習モデルから直接重みを取得している違いなどがあるようです。
Timm Encoders
こちらは PyTorch Image Models(timm) で提供される事前学習モデルで、利用できるものは以下に一覧にされています。
timm は画像認識モデルのバックボーンの実装において便利な事前学習済みのモデルを提供するライブラリです。
Segmentation Models PyTorch の Timm Encoders では、timm の API (timm.create_model) を使ってバックボーンの実装を行っています。Timm Encoders の一覧のエンコーダを利用する際は、モデルのコンストラクタの encoder_name に tu-resnet34 のように一覧の名称に tu- を付加した名前を指定します。
DeepLabv3+ の論文でバックボーンに利用されている Xception は Available Encoders の中でも提供されていますが、 Atrous(Dilated) 畳み込みがサポートされていません。 Timm Encoders の Xception は Atrous 畳み込みがサポートされているので、論文の条件をできるだけ再現したい場合は Timm の事前学習済みモデル tu-xception41 を利用すると良さそうです。
環境構築
前段が長くなりましたが、実装の部分に入っていきたいと思います。今回は以下の環境で実装しました。
| CPU | Intel Core i7-12700 |
|---|---|
| GPU | NVIDIA GeForce RTX 3080 Ti |
| OS | Windows 11 |
| conda (Miniconda) | 23.3.1 |
| Python | 3.11.6 |
| PyTorch | 2.1.0 |
| CUDA | 11.8 |
| Segmentation Models PyTorch | 0.3.3 |
Segmentation Models PyTorch はドキュメントでは pip でのインストール方法が紹介されていますが、 conda-forge リポジトリでも提供されています。
PyTorch 等も含め、以下のコマンドによりインストールを行いました。
conda create -n seg python=3.11 conda activate seg conda install pytorch pytorch-cuda=11.8 scikit-learn segmentation-models-pytorch six -c pytorch -c nvidia
学習に用いるデータセット
DeepLabv3+ の論文ではデータセットとして VOC 2012 データセットが利用されており、ここでもこのデータセットを用いて学習を行うこととします。
VOC 2012 では以下のページにも記載されている通り、背景を含めた21カテゴリのセグメンテーション用のデータセットとなっています。
各カテゴリのインデックス、色の対応は以下のようになっています。
| index | label | color |
|---|---|---|
| 0 | background | (0, 0, 0) |
| 1 | aeroplane | (128, 0, 0) |
| 2 | bicycle | (0, 128, 0) |
| 3 | bird | (128, 128, 0) |
| 4 | boat | (0, 0, 128) |
| 5 | bottle | (128, 0, 128) |
| 6 | bus | (0, 128, 128) |
| 7 | car | (128, 128, 128) |
| 8 | cat | (64, 0, 0) |
| 9 | chair | (192, 0, 0) |
| 10 | cow | (64, 128, 0) |
| 11 | diningtable | (192, 128, 0) |
| 12 | dog | (64, 0, 128) |
| 13 | horse | (192, 0, 128) |
| 14 | motorbike | (64, 128, 128) |
| 15 | person | (192, 128, 128) |
| 16 | potted plant | (0, 64, 0) |
| 17 | sheep | (128, 64, 0) |
| 18 | sofa | (0, 192, 0) |
| 19 | train | (128, 192, 0) |
| 20 | tv/monitor | (0, 64, 128) |
Torchvision では VOC 2012 の API が提供されており、これを利用することで自動的に適切なフォルダ構成でデータがダウンロードできます。
この VOC 2012 データセットの内訳としては教師が1,464データで検証が1,449データとなっており、検証データに対して教師が少ないです。DeepLabv3+ の論文では教師データを追加して学習を行っていますが、ここではシンプルに実装することとしてこの API で提供されるそのままのデータ数で利用します。
学習コードの実装
DeepLabv3+ の論文や以下の実装も参考にしつつ簡略化した学習処理を実装します。
上記の実装ではデータセットやパラメータが細かく選択できるように実装されていますが、ここでは処理を絞って以下のように実装しました。
import argparse import datetime import logging import pathlib import random import numpy as np import segmentation_models_pytorch as smp import sklearn.metrics import torch import torch.backends.cudnn import torch.nn import torch.utils.data import torchvision import torchvision.datasets import torchvision.transforms import torchvision.transforms.functional as TF class CenterCropTransforms: def __init__(self, crop_size): self.crop_size = crop_size self.normalize_mean = [0.485, 0.456, 0.406] self.normalize_std = [0.229, 0.224, 0.225] def __call__(self, image, label): image = TF.resize(image, [self.crop_size], torchvision.transforms.InterpolationMode.BILINEAR) label = TF.resize(label, [self.crop_size], torchvision.transforms.InterpolationMode.NEAREST) image = TF.center_crop(image, [self.crop_size, self.crop_size]) label = TF.center_crop(label, [self.crop_size, self.crop_size]) image = TF.to_tensor(image) label = torch.from_numpy(np.array(label, dtype=np.uint8)) image = TF.normalize(image, self.normalize_mean, self.normalize_std) return image, label def fix_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True def setup_logger(name, logfile): logger = logging.getLogger(name) logger.setLevel(logging.INFO) formatter = logging.Formatter("%(asctime)s %(name)10s %(levelname)8s %(message)s") streamhandler = logging.StreamHandler() streamhandler.setFormatter(formatter) logger.addHandler(streamhandler) filehander = logging.FileHandler(logfile) filehander.setFormatter(formatter) logger.addHandler(filehander) return logger def pred_per_epoch(model, device, dataloader, criterion, num_classes, optimizer=None, scheduler=None): total_loss = 0.0 preds_list = [] labels_list = [] with torch.set_grad_enabled(model.training): for images, labels in dataloader: images: torch.Tensor = images.to(device, dtype=torch.float32) labels: torch.Tensor = labels.to(device, dtype=torch.long) output = model(images) loss = criterion(output, labels) if model.training and not optimizer is None: optimizer.zero_grad() loss.backward() optimizer.step() pred = output.max(dim=1)[1] total_loss += loss.item() * np.prod((images.shape[0], images.shape[2], images.shape[3])) labels_list.extend(labels.flatten().cpu().tolist()) preds_list.extend(pred.flatten().detach().cpu().tolist()) if model.training and not scheduler is None: scheduler.step() preds_list = np.array(preds_list).flatten() labels_list = np.array(labels_list).flatten() cm = sklearn.metrics.confusion_matrix(labels_list, preds_list, labels=np.arange(num_classes)) iou = np.diag(cm) / (cm.sum(axis=1) + cm.sum(axis=0) - np.diag(cm)) scores = {"loss": total_loss / len(preds_list), "miou": np.nanmean(iou)} return scores def main(args=None): parser = argparse.ArgumentParser() parser.add_argument("--name", type=str, default="train") parser.add_argument("--backbone", type=str, default="tu-xception41") parser.add_argument("--output_stride", type=int, default=16, choices=[8, 16]) parser.add_argument("--epochs", type=int, default=50) parser.add_argument("--lr", type=float, default=0.01) parser.add_argument("--batch_size", type=int, default=16) parser.add_argument("--val_batch_size", type=int, default=16) parser.add_argument("--crop_size", type=int, default=512) parser.add_argument("--cpu", action="store_true") parser.add_argument("--random_seed", type=int, default=1) parser.add_argument("--download", action="store_true", default=False) args = parser.parse_args(args) fix_seed(args.random_seed) num_classes = 21 output_path = pathlib.Path("outputs", f"{datetime.datetime.now():%Y%m%d-%H%M%S}_{args.name}") output_path.mkdir(parents=True) logger = setup_logger(__name__, output_path.joinpath("run.log")) logger.info("Running on PyTorch %s", torch.__version__) logger.info("Parameters:") for k, v in vars(args).items(): logger.info(" --%s=%s", k, v) if torch.cuda.is_available() and not args.cpu: device = torch.device("cuda") logger.info("Using GPU: %s from %s devices", torch.cuda.current_device(), torch.cuda.device_count()) else: device = torch.device("cpu") train_dst = torchvision.datasets.VOCSegmentation( root="./data", year="2012", image_set="train", download=args.download, transforms=CenterCropTransforms(args.crop_size), ) val_dst = torchvision.datasets.VOCSegmentation( root="./data", year="2012", image_set="val", transforms=CenterCropTransforms(args.crop_size), ) train_loader = torch.utils.data.DataLoader(train_dst, batch_size=args.batch_size, shuffle=True, drop_last=True) val_loader = torch.utils.data.DataLoader(val_dst, batch_size=args.val_batch_size, shuffle=True) logger.info("VOC Dataset, Train set: %d, Val set: %d", len(train_dst), len(val_dst)) model = smp.DeepLabV3Plus( encoder_name=args.backbone, encoder_output_stride=args.output_stride, classes=num_classes, ) model.to(device) optimizer_params = [ dict(params=model.encoder.parameters(), lr=0.1 * args.lr), dict(params=model.decoder.parameters(), lr=args.lr), dict(params=model.segmentation_head.parameters(), lr=args.lr), ] optimizer = torch.optim.SGD(params=optimizer_params, lr=args.lr, momentum=0.9, weight_decay=1e-4) scheduler = torch.optim.lr_scheduler.PolynomialLR(optimizer, total_iters=args.epochs, power=0.9) criterion = torch.nn.CrossEntropyLoss(ignore_index=255) best_score = 0.0 for epoch in range(1, 1 + args.epochs): model.train() train_scores = pred_per_epoch( model=model, device=device, dataloader=train_loader, criterion=criterion, num_classes=num_classes, optimizer=optimizer, scheduler=scheduler, ) logger.info("Epoch %3d, Train, loss %5f, mIoU %5f", epoch, train_scores["loss"], train_scores["miou"]) model.eval() val_scores = pred_per_epoch( model=model, device=device, dataloader=val_loader, criterion=criterion, num_classes=num_classes, ) logger.info("Epoch %3d, Val , loss %5f, mIoU %5f", epoch, val_scores["loss"], val_scores["miou"]) if val_scores["miou"] >= best_score: torch.save(model.state_dict(), output_path.joinpath("model.pth")) best_score = val_scores["miou"] if __name__ == "__main__": try: main() except KeyboardInterrupt: pass
実装のポイントとしては以下のようなところです。
- 前述の通り、データセットには Torchvision の
VOCSegmentationを用いています。初めて実行する際にコマンドライン引数に--downloadを指定することで、./data配下にデータセットがダウンロードされます。 VOCSegmentationはデフォルトでは入力画像とラベル画像の2つの PIL のImageオブジェクトなので、CenterCropTransformsにより2つの画像を同時に処理してテンソルに変換する処理を定義し、VOCSegmentationの引数transformsに渡しています。ここでは教師・検証データともに中央をクロップしているだけですが、教師データに対して適切なオーギュメンテーションを施すなど工夫可能なポイントかと思います。- 学習のログには
loggingによるロガーを用いています。setup_loggerで行っているような多少のセットアップが必要になりますが、コンソールとファイルへの同時出力や、時刻ログによるパフォーマンスの確認ができるので、学習ログの記録に私はよく利用しています。 - モデルの初期化は Segmentation Models PyTorch を利用し、
smp.DeepLabV3Plusで呼び出しています。バックボーンと出力ストライドをコマンドライン引数から指定できるようにしています。 SGDの引数paramsに対してモデルのモジュールごとに初期学習率を与えています。エンコーダには事前学習モデルを用いるので、 他より低めの0.1倍の学習率としています。- 教師データと検証データに対する処理を統一するため、下記の記事で紹介していたように
pred_per_epoch関数で予測部分の処理を統一しています。
ちなみに、fix_seed にてシード値を固定して再現性を確保するような処理を行っていますが、筆者の環境では GPU で実行した際は同じコマンドで実行しても同一の結果にはならず、再現性は確認できませんでした。一方、--cpu オプションにより CPU で実行した場合には同じコマンドに対して再現性が確認できました。
学習結果
実装した学習コードを用いて、エンコーダとして以下のバックボーンに対して学習した結果を確認します。
resnet34: Torchvision の事前学習モデルtu-resnet34: Timm の事前学習モデルで Atrous(Dilated) 畳み込みをサポートtu-xception41: Timm の事前学習モデルで Atrous(Dilated) 畳み込みをサポートmobilenet_v2: Torchvision の事前学習モデルtu-mobilenetv2_050: Timm の事前学習モデルで Atrous(Dilated) 畳み込みをサポート
ここではエポック数は50として、クロップサイズ --crop_size を320, 400, 512の3パターンで実行してみます。
クロップサイズ 320 --crop_size=320
以下のコマンドで学習した結果を確認します。
python main.py --backbone="resnet34" --crop_size=320 --epochs=50 python main.py --backbone="tu-resnet34" --crop_size=320 --epochs=50 python main.py --backbone="tu-xception41" --crop_size=320 --epochs=50 python main.py --backbone="mobilenet_v2" --crop_size=320 --epochs=50 python main.py --backbone="tu-mobilenetv2_050" --crop_size=320 --epochs=50
ログファイルに出力された検証データに対する mIoU をプロットします。
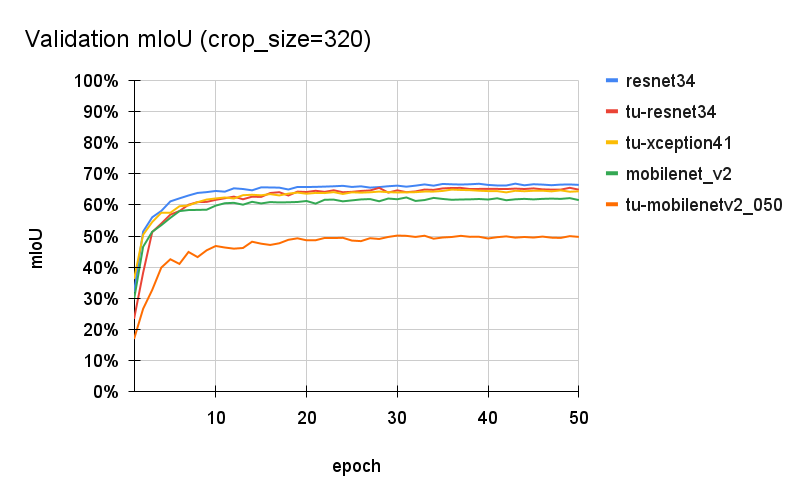
全ての結果で概ね20エポック程度で学習が落ち着いていおり、事前学習モデルの利用による効果が確認できます。しかし、 tu-mobilenetv2_050 だけが極端に精度が低い結果になり、原因はわかりませんが他のバックボーンに対して上手く学習できてない可能性が考えられます。その他の4つのバックボーンは65%前後に落ち着いており、Torchvison の事前学習モデルの resnet34 が一番良い結果となりました。
tu-resnet34 や tu-xception41 は Atrous(Dilated) 畳み込みをサポートしているので、Atrous 畳み込みの導入の効果があれば tu-resnet34 や tu-xception41 の方が良い結果になるかと思いますが、違う結果となりました。一方で、DeepLabv3 の論文でもクロップサイズが小さいと性能が低下する結果が得られており、高解像の特徴量の畳み込みを目的とした Atrous 畳み込みを活かすにはクロップサイズ 320では不十分なのかもしれません。次のクロップサイズ400のケースも確認してみたいと思います。
クロップサイズ 400 --crop_size=400
同様に以下のコマンドで学習した結果を確認します。
python main.py --backbone="resnet34" --crop_size=400 --epochs=50 python main.py --backbone="tu-resnet34" --crop_size=400 --epochs=50 python main.py --backbone="tu-xception41" --crop_size=400 --epochs=50 python main.py --backbone="mobilenet_v2" --crop_size=400 --epochs=50 python main.py --backbone="tu-mobilenetv2_050" --crop_size=400 --epochs=50
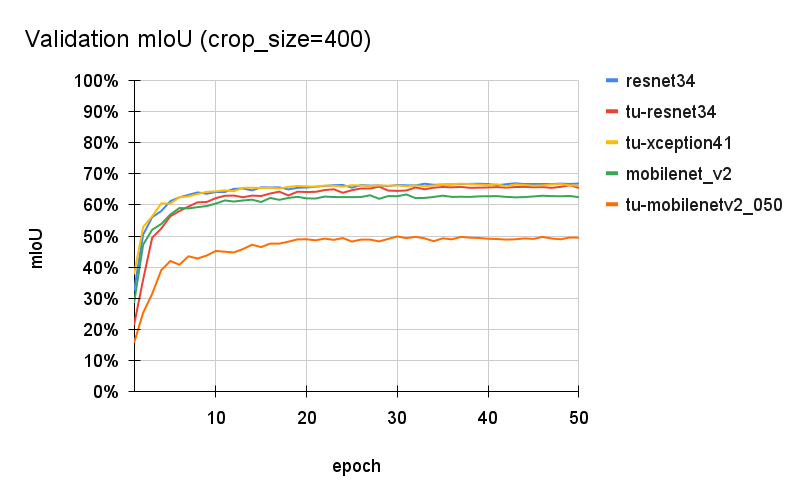
こちらもクロップサイズ320のケースと同様に、概ね20エポック程度で学習が落ち着き、 tu-mobilenetv2_050 だけが精度の低い結果となりました。他のバックボーンについては、tu-resnet34 や tu-xception41 の精度が向上し、 resnet34 とほぼ同等の精度が得られました。やはり、入力の画像サイズが大きい方が Atrous 畳み込みの恩恵は出やすいのかもしれません。
クロップサイズ 512 --crop_size=512
同様に以下のコマンドで学習した結果を確認します。
python main.py --backbone="resnet34" --crop_size=512 --epochs=50 python main.py --backbone="tu-resnet34" --crop_size=512 --epochs=50 python main.py --backbone="tu-xception41" --crop_size=512 --epochs=50 python main.py --backbone="mobilenet_v2" --crop_size=512 --epochs=50 python main.py --backbone="tu-mobilenetv2_050" --crop_size=512 --epochs=50
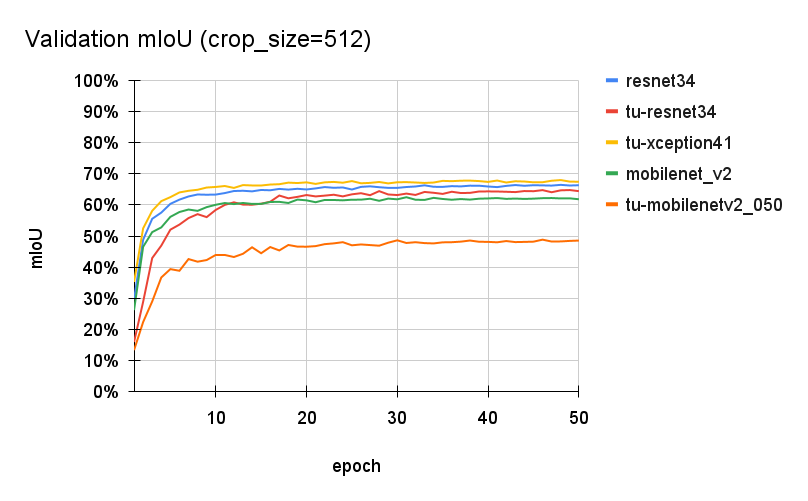
ここでは tu-xception41 が一番良い結果となり、高解像度の画像に対する適用性が確認できました。しかし、クロップサイズが512の場合に tu-xception41 だけが極端に学習に時間がかかるようになり、他のバックボーンは学習時間が2~3時間なのに対して tu-xception41 は1日程度要しました。。。原因はよくわかりません。
あとがき
実装や学習結果の確認を通して DeepLabv3+ の全体像が把握できました。応用タスクの実装におけるベースラインとして活用していきたいと思います。